Technik einfach und verständlich erklärt.
Sie können nützliches zu einem interessanten Thema berichten? Dann schreiben sie selbst einen Artikel auf Technikpedia!
Technik von Profis erklärt
Auf www.technikpedia.de können Sie Informationen zu verschiedenen Themen aus der Technik und Informatik finden. Durch verschiedene Editoren sind die Artikel besonders informativ und aussagekräftig.
XT Commerce Teil 1 : Installation
Allgemeines
Heute möchte ich euch das Shopsystem XT-Commerce vorstellen. Entwickelt wurde XT-Commerce aus dem Quellcode des OpenSource-Projekts OS-Commerce heraus. Daher ist die Benutzung dieser Software auch kostenlos. Auf der offiziellen Homepage wird sie allerdings nur mit kostenpflichtigem Support vertrieben. Die Software selbst kann in viele Foren kostenlos heruntergeladen werden.
Installation
Als erstes müsst ihr das heruntergeladene Archiv (meist ein ZIP-Archiv) entpacken. Den Inhalt des Ordners „xtcommerce“ ladet ihr dann auf eurem Webserver in das gewünschte Verzeichnis. Die Wartezeit bietet eine gute Gelegenheit die Datenbankverbindung und die Zugangsdaten eures Webservers herzusuchen oder eine neue Datenbank anzulegen. Nach Möglichkeit sollte für XT-Commerce eine eigene Datenbank genutzt werden, damit es nicht zu Überschneidungen bei den Tabellennamen kommt.
Nachdem alle Dateien erfolgreich hochgeladen wurden, könnt ihr euren Shop im Webbrowser aufrufen. Um die Installation zu starten hängt ihr an die URL noch „/xtc_installer/“ an. Auf der ersten Seite wird euer Webserver auf Kompatibilität mit eurer XT-Commerce-Version geprüft. Wenn in allen Feldern ein „OK“ steht, könnt ihr noch eure Sprache aus den verfügbaren Sprachen auswählen.
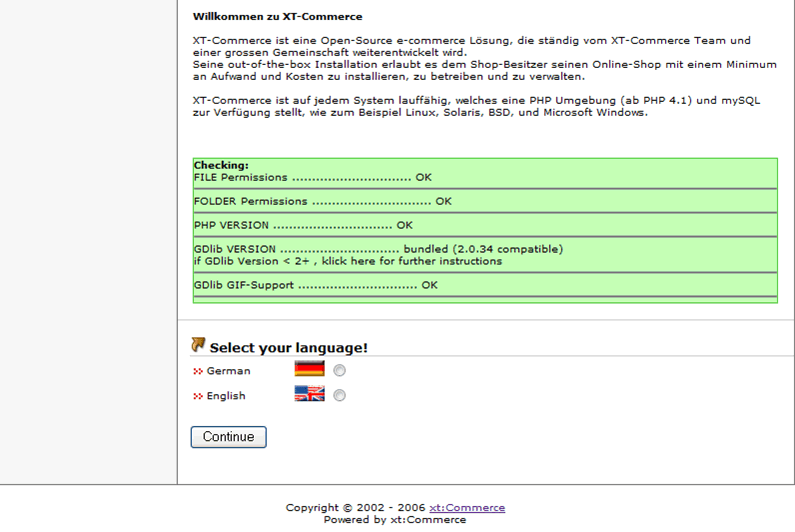
Im nächsten Schritt geht es um die Datenbank. Anfänger sollten die beiden Checkboxen „Importiere die XT-Commerce Datenbank“ und „Automatische Konfiguration“ unbedingt aktiviert lassen. In den Bereich „Datenbank Informationen“ müssen jetzt die vorher beschafften Daten zu eurer Datenbank eingetragen werden. Die Felder im Bereich „Webserver Informationen“ sollten bereits richtig ausgefüllt sein. Falls ihr sicher seid, dass die eingegebenen Verzeichnispfade falsch sind, müsst ihr hier entsprechend korrigieren.

Nach einem Klick auf Continue sollte die Meldung „Eine Testverbindung zur Datenbank war erfolgreich.“ erscheinen. Falls das nicht der Fall ist, solltet ihr zurückgehen und eure Zugangsdaten für die Datenbank überprüfen. Nach erfolgreicher Datenbankverbindung und einem weiteren Klick auf Continue werden die benötigten Tabellen in der Datenbank erstellt und mit den Standardwerten gefüllt. Das kann je nach Webserver eine Weile dauern. Bei Erfolg sollte die Meldung „Der Datenbank-Import war erfolgreich.“ ausgegeben werden.
Im nächsten Schritt werden die Konfigurationsdateien angepasst. Die hier bereits eingetragenen Informationen sollten im Normalfall passen. Ist dem nicht so könnt ihr die Eingaben wieder anpassen. Interessant ist auf dieser Seite der letzte Teil. Es wird gefragt wo die Sessions gespeichert werden sollen. Ich empfehle die Speicherung in der Datenbank, da es zum Speichern in eine Datei ein weiteres, für alle zugängliches Verzeichnis auf dem Webserver bedarf.

Bei Erfolg könnt ihr jetzt die Informationen über den Shop-Betreiber und den Shop selbst eintragen. Das Passwort solle dabei aus mindesten fünf Zeichen bestehen. Die angegebene E-Mail-Adresse wird für die Kommunikation eures Shops mit dem Kunden (zum Beispiel zur Auftragsabwicklung) benötigt und sollte deshalb unbedingt existieren. Für die einzelnen Vorgänge können später im Konfigurationsmenü noch unterschiedliche Adressen angegeben werden. Die angegebene Anschrift wird bei der Versandabwicklung als Absender-Adresse genutzt. Ich empfehle das „automatische Einstellen der Steuerzonen“ auf Ja zu belassen.
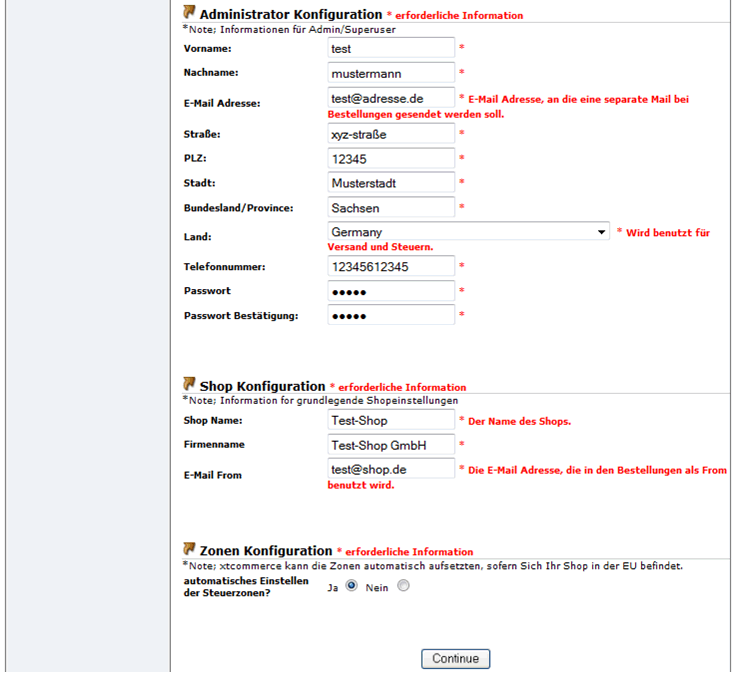
Auf der nächsten Seite können Shop spezifische Konfigurationen für Gäste und Standardkunden angelegt werden. In der Regel sollten die voreingestellten Konfigurationen passend sein. Wichtig ist, dass die Steuer bei Endkunden mit angezeigt werden muss.

Damit ist die Installation abgeschlossen. Um Manipulationen an eurem Shop zu verhindern, solltet ihr jetzt noch das gesamte Verzeichnis „xtc_installer“ auf eurem Webserver löschen und die Zugriffsrechte für die Dateien
- /SHOP/includes/configure.php
- /SHOP /includes/configure.org.php
- /SHOP /admin/includes/configure.php
- /SHOP /admin/includes/configure.org.php
auf read-only (auf Windows-Server) bzw. 444 (auf Unix-Systemen) setzten.
Tinte Befüllung: HP Nr.45-51645a
Um eine Tinte Nr. 45 von HP wieder zu befüllen muss die Tintenpatrone zuerst auf den Kopf gestellt werden. Du entfernst einfach den Aufkleber der über dem Loch in der Tinte ist und drückst mit einem spitzen Gegenstand die Metallkugel in die Patrone rein. Jetzt füllst du vorsichtig die neue Ersatz- Tinte in die Patrone hinein. Du musst versuchen die Patrone ganz voll zu machen, denn es darf keine Luft mehr in der Tintenpatrone übrig bleiben. Jetzt muss das Einfüllloch der Tintenpatrone mit einer neuen Stahlkugel verschlossen werden. Das Loch sollte zur Sicherheit auf jeden Fall jetzt wieder mit einem Aufkleber überklebt werden, damit hier sichergestellt ist das keine Tinte mehr auslaufen kann. Nun muss die Tinte wieder umgedreht und einige male auf den Tisch geklopft werden, damit die Luftblasen vom Druckkopf weg nach oben steigen. Anschließend wartest du bis keine Tinte mehr aus den Düsen tropft und reinigt diese mit einem Taschentusch oder ähnlichem. Jetzt kann die Tinte in den Drucker eingesetzt werden. Anschließend muss einmal der Reinigungsvorgang vom Gerät über den Computer gestartet werden.
Patronenerkennung nach Tinten Befüllung umgehen: HP Nr.45-51645a
Die aufgefüllte Tinte Nr. 45 aus dem Gerät ausbauen und die Tinte mit den Düsen nach unten aufstellen, sodass man die Kontakte alle sehen kann. Nun die obersten vier Kontakte in der linken Kontaktspalte abkleben, sodass hier kein Kontakt mehr zustande kommt und die Patrone wieder einsetzen. Die auftauchenden Fehlermeldungen ignorieren und die Tinten nach ca. 20 Sekunden wieder ausbauen und die Klebestreifen entfernen. Das gleiche machen wir jetzt mit den obersten vier Kontakten der rechten Kontaktspalte von der Tinte. Auch hier die Tinte wieder für ca. 20 Sekunden mit abgelebten Kontakten in das Gerät einbauen warten bis der Schlitten hin und her gefahren ist und die Fehler ignorieren. Anschließend auch hier die Klebestreifen der Tinte wieder entfernen und nun sollte die Patronenerkennung bei der Tinte nicht mehr auftauchen.
Keinen Tintenstrahldrucker? Dann schau mal unter Toner für Laserdrucker.
Farbänderungen in Photoshop
Heute möchte ich euch einmal in einem kleinen Video Tutorial zeigen wie man die Farben von verschiedenen Objekten relativ einfach manipulieren kann. Dazu benötigt ihr natürlich Adobe Photoshop. Ich benutze zur Zeit noch die Version CS3. Solltet ihr eine andere Version benutzen, könnten die Objekte: „Neue Füll- oder Einstellungsebene erstellen“ und „Selektive Farbkorrektur“ sich an einem anderen Platz befinden.
Ich hoffe, euch hat mein kleines Video gefallen und auch geholfen!
Temporäre Tabellen in einer Datenbank
Die Idee einer temporären Tabelle
Wer es noch nicht kennt, dem möchte ich als Tipp temporäre Tabellen einer Datenbank vorstellen. Temporäre Tabellen gibt es für alle gängigen Datenbanksysteme. Ich verwende hier Microsoft SQL.
Temporäre Tabellen kann man zum Beispiel prima gebrauchen, wenn man sich mal eben schnell was merken will. Oder wenn man Daten zum Bearbeiten zwischenspeichern will eignet sich die schnelle und saubere Methode prima. Man braucht nicht erst eine View erzeugen oder per Hand eine Tabelle anlegen. Wie der Name vielleicht vermuten lässt, werden temporäre Tabellen nach Gebrauch, meistens nach Beendigung der Verbindung, gelöscht.
Erzeugung einer temporären Tabelle
Temporäre Tabellen können wie jede andere Tabelle mit dem Befehl CREATE TABLE <tabellenname> definiert und erzeugt werden. Beim Namen muss lediglich eine oder zwei Rauten (# oder ##) vorangestellt werden. Egal mit welcher Datenbank man gerade arbeitet, temporäre Tabellen werden intern in der Systemdatenbank tempdb gespeichert und sind aber überall verfügbar. Über den Speicherort braucht man sich in der Praxis keine Gedanken machen, da das Datenbankmanagementsystem sich automatisch darum kümmert. Nach der Beendigung der Datenbank-Session werden die Tabellen vom Datenbanksystem automatisch gelöscht und die Daten gehen verloren.
Ein echter Vorteil erschließt sich erst mit der Möglichkeit der direkten Erzeugung von temporär gefüllten Tabellen aus einem Select-Befehl. Das sieht dann zum Beispiel so aus:
SELECT * INTO #tempdaten FROM tabelle
So hat man direkt die von einem Select gelieferten Daten in einer temporären Tabelle zwischengespeichert. Man beachte, die Reihenfolge der Schlüsselwörter: erst select, dann into und zum Schluss from (und nicht erst from und dann into, sonst geht’s nicht).
Jetzt kann man nach Belieben die Daten weiterverarbeiten und Speichern.
Temporäre Tabellen in Stored Procedures
Eine wunderbare Verwendungsmöglichkeit ergibt sich bei gespeicherten Prozeduren (stored procedures). So können in einer temporären Tabelle prima die Daten manipuliert und dann automatisch weiterverarbeitet oder in andere Tabellen zurückgespeichert werden.
Sichtbarkeit – Der Unterschied zwischen einem und zwei Rauten (#) im Tabellenname (#tabellenname und ##tabellenname)
Werden bei dem Namen einer temporären Tabelle nur eine Raute (#) angegeben, so ist die Tabelle nur in der eigenen Verbindung sichtbar. Andere Verbindungen können nicht darauf zugreifen.
Bei temporären Tabellen mit zwei vorangestellten Rauten (##) sind diese auch für andere Sessions bzw. Verbindungen verfügbar.
Beide Arten von temporären Tabellen werden mitsamt ihren Inhalten gelöscht, wenn die Verbinung bzw. Session, in der die Tabelle erzeugt wurde, beendet wird.
Mit Openoffice Calc CSV-Dateien Speichern und unter Windows Einstellungen des Formates richtig festlegen
Wer mit der Tabellenkalkulation Calc von Openoffice.org (OOO) (Version 3.00 – Freeware) unter Windows schon einmal Dateien im CSV (comma seperated value)-Format speichern wollte, dem ist vielleicht aufgefallen, dass ihm da diverse Auswahlmöglichkeiten fehlen.
Es kann unter Umständen vorkommen, das man CSV-typische Einstellungen wie den Zeichensatz oder die Trennzeichen nicht auswählen kann. Standardmäßig wird immer im Zeichensatz latin-1 gespeichert, sowie ein Semikolon (;) als Feldtrenner und Anfürungsstriche („) als Texttrenner. Das Programm Openoffice.org speichert einfach ab, ohne vorher nachzufragen, wie die CSV-Datei nun genau aussehen kann.
 Normalerweise kann man das Optionsfenster mit den Einstellungen zu den CSV-Dateien beim Speichern mit der Option „Filter Options“ bzw. in deutsch „Filteroptionen“ aktivieren. Das Feld ist aber unter Umständen, wie es bei mir der Fall war, aus unerklärlichen Gründen deaktiviert und ausgegraut.
Normalerweise kann man das Optionsfenster mit den Einstellungen zu den CSV-Dateien beim Speichern mit der Option „Filter Options“ bzw. in deutsch „Filteroptionen“ aktivieren. Das Feld ist aber unter Umständen, wie es bei mir der Fall war, aus unerklärlichen Gründen deaktiviert und ausgegraut.
Des Rätsels Lösung ist, dass Openoffice.org in den Standardeinstellungen den Speichern-Dialog von Windows verwendet. Wenn wir den OOO-eigenen Speichern-Dialog verwenden, dann sollte alles wie erhofft funktionieren.
Den Speichern-Dialog kann man unter den Einstellungen (Im Menü „Extras“ → „Optionen“ → „OpenOffice.org“ → „Allgemein“) ändern. Hier bei „Öffnen/Speichern-Dialoge“ das Häkchen „OpenOffice.org-Dialoge verwenden“ anklicken.

Sobald wir diese Einstellung vorgenommen haben, sieht unser Speichern-Dialog ein wenig anders aus.

Jetzt können wir hier „Filtereinstellungen bearbeiten“ anklicken. Und schön können wir nach einem Klick auf Speichern unsere gewünschten Einstellungen vornehmen.

Siehe da, Zeichensatz, Feldtrenner, Texttrenner – Alles ist da!
Fehler beim Daten Import / Export aus einer Excel-Datei mit dem Microsoft Server Management Studio 10 in eine Microsoft SQL Server 2008 Datenbank
Als ich neulich Daten aus einer Excel-Tabelle in eine MS-SQL-Datenbank importieren wollte, bin ich fast verzweifelt. Mit dem alten SQL Enterprise Server Manager 2000 ging das immer recht einfach. Aber mit den SQL-Tools von 2008 hatte ich so meine Probleme.
Ich nutze den SQL Server-Import/Export-Assistent.
Die Meldungen waren folgende:
– Überprüfung wird ausgeführt (Warnung)
Meldungen
Warnung 0x802092a7: 1-Datenflusstask: Daten werden möglicherweise abgeschnitten, weil Daten aus der [Spaltenname]-Datenflussspalte mit der Länge 255 in die [Spaltenname]-Datenbankspalte mit der Länge 40 eingefügt werden.
(SQL Server-Import/Export-Assistent)
Warnung 0x802092a7: 1-Datenflusstask: Daten werden möglicherweise abgeschnitten, weil Daten aus der [Spaltenname]-Datenflussspalte mit der Länge 255 in die [Spaltenname]-Datenbankspalte mit der Länge 40 eingefügt werden.
(SQL Server-Import/Export-Assistent)
und
– Wird ausgeführt (Fehler)
Meldungen
Fehler 0xc020901c: 1-Datenflusstask: Fehler bei ‚Ausgabespalte ‚[Spaltenname]‘ (21)‘ für ‚Ausgabe ‚Ausgabe der Excel-Quelle‘ (9)‘. Folgender Spaltenstatus wurde zurückgegeben: ‚Der Text wurde abgeschnitten, oder ein oder mehrere Zeichen hatte(n) auf der Zielcodeseite keine Entsprechung.‘.
(SQL Server-Import/Export-Assistent)
Fehler 0xc020902a: 1-Datenflusstask: Fehler bei ‚Ausgabespalte ‚[Spaltenname]‘ (21)‘ aufgrund abgeschnittener Daten. Die Abschneidezeilendisposition in ‚Ausgabespalte ‚[Spaltenname]‘ (21)‘ gibt an, dass der Vorgang bei einem Abschneidefehler nicht ausgeführt werden kann. Es wurde ein Abschneidefehler im angegebenen Objekt der angegebenen Komponente festgestellt.
(SQL Server-Import/Export-Assistent)
Fehler 0xc0047038: 1-Datenflusstask: SSIS-Fehlercode ‚DTS_E_PRIMEOUTPUTFAILED‘. Die PrimeOutput-Methode in ‚Komponente ‚Quelle – Tabelle1$‘ (1)‘ hat den Fehlercode 0xC020902A zurückgegeben. Die Komponente gab einen Fehlercode zurück, als das Pipelinemodul ‚PrimeOutput()‘ aufgerufen hat. Die Bedeutung des Fehlercodes wird von der Komponente definiert. Der Fehler ist jedoch schwerwiegend, und die Ausführung der Pipeline wurde beendet. Möglicherweise wurden bereits Fehlermeldungen veröffentlicht, die weitere Fehlerinformationen beinhalten.
(SQL Server-Import/Export-Assistent)

Ich hatte mit zahlreichen Einstellungen rumprobiert.

Alle Spaltentypen sollten konvertiert werden: Von VarChar nach varchar, von VarChar nach text und von Double nach int (in der Tabelle standen sowieso nur ganze Zahlen).
Wenn Daten zu groß waren (was meiner Meinung nach bei keinem Datensatz der Fall so war) sollten sie abgeschnitten werden und es sollte nicht mit einem Fehler angehalten werden. Auch habe ich die Daten nach Sonderzeichen hin überprüft. („Zeichen haben keine Entsprechung auf der Zielcodeseite“). Eigentlich war alles in Ordnung. Weder waren die Daten zu lang, noch gab es Probleme mit dem Zeichensatz.
Es half alles nichts. Ich konnte die Daten einfach nicht importieren. Des Rätsels Lösung habe ich im Internet direkt auf der Internetseite von Microsoft gefunden.
http://support.microsoft.com/kb/281517/EN-US/ bzw. http://support.microsoft.com/?scid=kb%3Bde%3B281517&x=10&y=12
Beim Importieren von Daten einer Jet OLEDB 4.0 Datenquelle mit Hilfe der „Data Transformation Services (DTS)“ und dem Microsoft OLE DB provider für Jet, was ja hier der Fall ist, kann man folgende Werte in der Registry(!) ändern:
Achtung: Registry vorher sichern und alle Änderungen auf eigene Verantwortung!
Einfach in der Registry des Computers, auf dem der Assistent läuft (der Clientcomputer) den Wert von HKEY_LOCAL_MACHINE\Software\Microsoft\Jet\4.0\Engines\Excel\TypeGuessRows auf 0 setzen.

Der Wert für TypeGuessRows steht für die Anzahl der Sätze, die von der Excel-Tabelle eingelesen werden sollen, um den Datentyp zu erraten. Wenn das fehl schlägt, dann funktioniert das Importieren nicht.
Gerade bei Feldern mit Texten weiß der Import-Assistent nicht, wie er sie behandeln soll. Bei Texte größer als 255 Zeichen wird der Datentyp „text“ geraten, ansonsten „varchar“. Wenn der Text im Problemfeld in den ersten paar Zeilen nicht länger als 255 Zeichen ist, dann wird der Datentyp varchar geraten und stimmt nicht mit dem Zieldatentyp „text“ überein. In meinem Fall ging es wohl eher um kurzen Text, der in eine Spalte mit der Länge von 40 eingefügt werden sollte. Obwohl kein Datensatz in der entsprechenden Spalte mehr als 40 Zeichen hatte.
Ich hatte auch keine andere Möglichkeit gefunden den Datentyp zu überschreiben. Mit dem Wert bei TypeGuessRows von 0, wird nun scheinbar(!) nicht mehr geraten.
Keine Ahnung, wozu das gut sein soll und warum man das nur in der Registry ändern kann.
Laut der Seite von Microsoft sind in der Registry bei TypeGuessRow nur Werte von 0 bis 16 zulässig. Wenn man den Wert 0 wählt, werden alle Zeilen (bis 16384) eingelesen, um den korrekten Datentyp zu bestimmten. Das Ganze kann bei großen Datenbeständen somit sehr langsam werden. Wer nicht in der Registry rumspielen will, der muss sicherstellen, das in den ersten 8 Datensätzen mindestens einer ist, der den Datentyp am besten ein/ausgrenzt, also in unserem Fall, der im Textfeld mindestens 255 Zeichen enthält.
Auf der Seite von Microsoft steht sogar beschrieben, wie man das Problem nachbauen kann.
Wie gesagt: Keine Ahnung, warum das Importieren aus einer Excel-Datei in meiner Datenkonstellation nur mit einer Einstellungsänderung in der Registry funktioniert. Vielleicht hatte ich auch irgendwo einen Denkfehler. Aber mit diesem Kniff hat es prima funktioniert.
HTML CSS Style: Element auf ein anderes verschieben…
…, ohne dass ein störender Platzhalter zurück bleibt
Das Problem:
Sie wollen bei der HTML-Seitengestaltung ein Element über ein anderes verschieben. Das Problem dabei kann manchmal sein, dass das verschobene Bild an der ursprünglichen Stelle einen unschönen Platzhalter hinterlässt.
Zur besseren Beschreibung habe ich folgendes, an der Praxis angelehntes, Problem konstruiert: (siehe Skizzen)

In einem Element (schwarzer Rahmen) befinden sich 2 weitere Elemente, zum Beispiel ein Bild (blauer Rahmen) und ein kleines weiteres Bild (roter Rahmen).
Die beiden inneren Elemente (rot und blau) sind mittig im äußeren Element (schwarz) ausgerichtet. (Bild 1)
Das kleine Bild (zum Beispiel eine Lupe), soll jetzt auf das große Bild platziert werden.
Bekannt ist, dass dies mit der Style-Möglichkeit „position“ geschehen kann. Bei dem HTML-Element, dass man verschieben möchte fügt man zum Beispiel folgendes CSS-Angabe hinzu:
style=“position: relative; left:50px; top:40px;“
Das bewirkt, dass das Element relativ zu seiner aktuellen Position um 50 Pixel nach unten und 40 Pixel nach rechts verschoben wird.

Häufig kommt es vor das man den Platz (auf Bild 2), wo sich das kleine Bild (roter Rahmen) ursprünglich befunden hatte als störend empfindet.
Wie kann man diesen Platz verschwinden lassen?
Die Lösung:
Des Rätsels Lösung ist ein sogenannter negativer Margin. Man fügt dem verschobenen Element einen negativen Abstand (margin) hinzu.
Beispiel:

Das kleine Element (roter Rahmen) hat eine Höhe von 20px. So fügt man ihm folgendes hinzu:
style=“margin-top: -20px;“
Dies bewirkt, dass der Abstand um 20 Pixel nach oben hin verkleinert wird. Somit verschwindet der störende Abstand.
Diese Lösung habe ich mit mehreren Browsern getestet.
Sie funktioniert mit: Mozilla Firefox 3.0.5, Internet Explorer (IE) 7.0, Google Chrome 1.0.153.43, Safari 3.2.1
Sie funktioniert nicht mit: Opera 9.6.3
Schützen sie ihren Computer vor Viren und anderen Schädlingen
Dafür gibt es viele Sicherheitslösungen. Ich möchte euch heute die Datenserver-Lösung von Avira AntiVir vorstellen. Sicherlich gibt es viele verschiedene Antivirenprogramme, die alle ähnliche Funktionalitäten beinhalten. Bei der Avira AntiVir-Lösung sind mir einige nette Funktionen aufgefallen. So zum Beispiel, dass man 2 verschiedene Versionen installieren kann. Das positive an den beiden Versionen:
- Konsolenversion: Die Konsolenversion von AntiVir kommt ohne grafische Benutzeroberfläche daher. Das Programm läuft nach Installation quasi nur als Dienst im Hintergrund. Dies hat den Vorteil, dass der Benutzer des PCs bzw. Servers nichts am Antivirenprogramm verändern oder verstellen kann. Dies kann nur der Administrator mit der Benutzeroberfläche-Version von AntiVir.
- AntiVir Server mit Benutzeroberfläche: Die Benutzeroberfläche-Version dient in diesem Fall quasi als Komandozentrale. Man kann über die Benutzeroberfläche die anderen Konsolenversionen verwalten, Aufträge einrichten, wie zum Beispiel: „führe ein Programmupdate zu einem bestimmten Zeitpunkt durch“, oder „überprüfe den Rechner zu dieser Uhrzeit auf Viren“ usw.
Somit hat in einem gut eingerichteten Netzwerk der Administrator jederzeit einfachen Zugriff auf die einzelnen Antivirenprogramme der Rechner. Für kleinere Netzwerke kann man auch auf jedem Rechner die Benutzeroberfläche installieren, damit jeder User sein Antivirenprogramm selbst konfigurieren kann. Auch hier kann man dann die anderen Rechner wieder über das Antivirenprogramm miteinander verbinden, und zum Beispiel von Rechner 1 aus die Konfiguration vom Antivirenprogramm des zweiten Rechners bearbeiten.
In beiden Fällen hat man dann über die Benutzeroberfläche Zugriff auf die verschieden angelegten Berichte und Reports von AntiVir. Darüber kann man schnell auf dem laufenden bleiben, ob denn das Netzwerk oder der Rechner von Schadsoftware betroffen war / ist.
Denn AntiVir hinterlegt nach jedem Update-Vorgang oder Suchdurchlauf einen Bericht ab, indem überprüft werden kann, ob alles Reibungslos von Statten ging, wie viele Dateien oder Verzeichnisse durchsucht wurden, welche Dateien in Quarantäne verschoben wurden usw.
Doch diese Softwarelösung ist nicht nur für kleine oder mittelgroße Netzwerke geeignet, auch bei sehr großen Netzwerken ist die Installation nicht mit allzu großen Mühen verbunden. Denn man kann für die Installation eine Art Script anlegen, welche sämtliche Benutzereingaben simuliert und das Antivirenprogramm vollkommen selbstständig und auf allen Rechnern identisch installiert. So muss man nur neben der Setup.exe von AntiVir eine Setup.inf anlegen und dort seine speziellen Installationsanweisungen hinterlassen. Welche Befehle es da gibt, steht alles in der Hilfe von AntiVir. Durch starten der Setup.exe wird dann die Installation vollautomatisch durchgeführt. Möchte man das Programm wieder deinstallieren, muss man nur wieder die Setup.exe mit folgenden Parametern starten: “/inf/AV Uninstall“. Nun entfernt sich das Programm selbst vom Rechner.
Die Fileserver-Lösung von AntiVir ist meiner Meinung nach ein Programm mit einem sehr hohen Selbststänigkeitsgrad. Die Installation funktioniert zum größten Tel automatisch (man muss halt nur einmal das Antivirenprogramm installieren, um die Auto-Installation für andere Rechner einzurichten). Durch die Aufträge, die man jeder installierten Version über die Benutzeroberfläche zuweisen kann, ist quasi das gesamte Netzwerk mit einer Antivirenlösung ausgestattet und immer auf dem aktuellsten stand.
Grüne Adressleiste bei Internet Explorer 7, Firefox 2 (nur mit passendem Addon), 3 und Opera 9.5:
Um für die oben genannten Browser bei der eigenen Domain eine grüne Adressleiste zu bekommen, ist ein EV-SSL Zertifikat nötig.

Die Vergabe des Zertifikates ist an folgende Kriterien gebunden:
- Überprüfung der Identität und der Geschäftsadresse des Antragstellers
- Sicherstellung, dass der Antragsteller auch ausschließlicher Eigentümer der Domain ist
Ob EV-SSL überhaupt Anklang findet, ist sehr fraglich. Grundsätzlich ließe sich durch die Verbesserung der Identitätsprüfung in der herkömmlichen SSL-Zertifikatsvergabepraxis das gleiche Ziel erreichen. Kleinere Webseitenbetreiber dürften sowieso kaum gewillt sein, Geld für ein weiteres Zertifikat auszugeben. Verisign etwa will 1299 Euro für ein Zertifikat, das ein Jahr lang gültig ist (¹). Zudem schützt auch das neue Verfahren beispielsweise nicht vor Phishing per Cross-Site-Scripting (³), bei dem gefälschte Inhalte in eine echte Seite eingeblendet werden.
Andere Zertifizierungsstellen bieten dieses EV-SSL Zertifikate (Extended Validation – Secure Sockets Layer) bereits für 488 $ jährlich an (²). Mit der kleinen Einschränkung, dass dieser grüne Balken dann nur bei Windows Vista-Betriebssystemen (und den oben genannten Browsern) angezeigt wird. An der Sicherheit der Datenübertragung ändert sich mit diesem neuen (und zugleich teuren) Zertifikat nichts.
Die Zertifizierungsstelle überprüft beim Aufrufen der Seite lediglich, ob ein Zertifikat auf dem Server installiert ist, und ob der Zertifikats-Inhaber mit dem der Zertifizierungsanmeldung übereinstimmt.
Sollte bei dieser Überprüfung irgendein Fehler auftreten bzw. die Daten nicht überein stimmen, wird ein roter Balken angezeigt.
Bei einer Seite ohne Zertifikate bleibt die Adressleiste weiß, bei einem älteren Zertifikat (SSL) färbt sich der Balken blau. Letzten Endes unterscheidet sich die blaue und grüne Färbung also nur in dem €-Betrag, den man für das Zertifikat ausgegeben hat. Mehr Geld bedeutet gleichzeitig bessere Färbung. Für Banken oder andere Unternehmen, bei denen wertvolle Daten (PIN & TAN oder Kreditkarten-Informationen) übermittelt werden, würde sich dieses EV-SSL Zertifikat lohnen, um dem Kunden mehr Sicherheit zu geben (auch wenn diese auf den 2ten Blick eigentlich nicht gegeben ist, im Gegensatz zur blauen Färbung).
(¹) http://www.verisign.de/ssl/buy-ssl-certificates/index.html
(²) http://www.digicert.com/ev-ssl-certification.htm
(³) http://www.heise.de/security/artikel/84149
PHP: Select Textfeld von MS-SQL-Datenbank, Zeichen werden abgeschnitten
Wer mit Hilfe der Scriptsprache PHP schon mal auf eine Microsoft-SQL-Datenbank zugegriffen hat, kennt sicherlich das Problem, dass in den Standardeinstellungen beim Auslesen von Textfeldern aus der Datenbank Zeichen beim Auslesen einfach abgeschnitten werden.
Das hängt damit zusammen, dass beim Server der Speicher für den maximal größtmöglichen Wert des Datenbankfeldes vorgehalten werden muss. So wäre dies bei Textfeldern Unmengen an Bytes. In den Standardeinstellungen von PHP ist die Größe der Textfelder, wenn sie ausgelesen werden, aus Performancegründen begrenzt (meist 4096).
Das Problem lässt sich folgendermaßen beheben:
Damit die Texte von Textfeldern nicht mehr nach so „wenigen“ Zeichen abgeschnitten werden, kann auf dem Server, auf welchem PHP installiert ist, die php.ini angepasst werden.
Man suche nach den Zeilen, die mit mssql.textlimit, und mssql.textsize beginnen. Wenn sie nicht vorhanden sind, fügt man sie ein, bzw. entkommentiert die Zeilen, die als Beispiel bereits in der php.ini als Kommentar vorhanden sind.
Man setzt für beide Zeilen einen neuen Wert in Bytes, der ausreichend für die Textfelder ist, die man selektieren möchte. Das sieht dann zum Beispiel so aus:
mssql.textlimit = 10000000
mssql.textsize = 10000000
Wer keinen Zugriff auf die php.ini hat, und über ODBC-Treiber auf die Datenbank zugreift, kann auch sein PHP-Skript anpassen:
Der Zauberbefehl für PHP heißt odbc_longreadlen. Mit ihm steuert man die Nutzung der Text-Felder. Die Syntax für diesen Befehl lautet:
int odbc_longreadlen ( int $result_id , int $length )
Die $result_id ist das Handle, das von odbc_exec zurückgeliefert wurde. Bei $length wird angegeben, wie viel Bytes PHP zurück liefern soll.
Beispiel:
$Sql = ‚SELECT textfeld FROM tabelle‘;
$cc = odbc_connect( $Dsn, $User, $Pwd );
$result = odbc_exec( $cc, $Sql );
odbc_longreadlen($result, 500000);
odbc_fetch_into($result, & $Data );
Daten mittels ASP von der SQL-Datenbank holen
Ein ähnliches Problem gibt es, wenn man Datenfelder vom Typ „Text“ aus der Datenbank mittels ASP holen möchte. Dort muss man einen besonderen Cursortyp angeben:
Dim Db
Set Db = Server.CreateObject( „ADODB.Connection“ )
Db.CursorLocation = 3 ‚ adUseClient
Neben CursorLocation gibt es noch CursorType und Locktype.
Cursortype:
– adOpenForwardOnly: 0
– adOpenKeyset: 1
– adOpenDynaset: 2
– adOpenStatic: 3
CursorLocation:
– adUseServer: 2
– adUseClient: 3
Locktype:
adLockUnspecified: -1
adLockReadOnly: 1
adLockPessimistic: 2
adLockOptimistic: 3
adLockLockBatch: 4
Kategorie
- Allgemein (55)
- Bildbearbeitung (1)
- Datenbanken (4)
- Empfangsgeräte (2)
- Internet (15)
- Multimedia (5)
- PC & Hardware (20)
- Tipps (8)
- XT-Commerce (1)
RSS
Monatsübersichten
